Exploration of Fundamental Techniques toward Intelligent Chinese Information Retrieval for the Internet
Lee-Feng Chien
Institute of Information Science, Academia Sinica, Taipei, Taiwan, R.O.C.
Tel: 886-2-2788-3799 ext. 1801
E-mail: lfchien@iis.sinica.edu.tw
Fax: 886-2-2782-4814
Abstract
In order to pursue high performance of Chinese information access on the Internet, Csmart project was launched at Academia Sinica four year ago. The whole research of the project consists of four major issues: Information Retrieval, Information Filtering and Knowledge Discovery, Speech and Natural Language Interface, and Searching Engines and Language Processing Tools. The main purpose of this paper is on the basis of running the project to point out several fundamental research issues and attempts to present some preliminary ideas toward feasible solutions. For this reason, the problems of intelligent information retrieval researches with the Chinese language have been briefly reviewed in advance and each of the ongoing research tasks with preliminary technical ideas described in short. We hope it will have a little bits of help for researchers who are interested in Chinese Information Retrieval and just finding more challenging problems.
I. Introduction
With the rapid growth in the number of electronic resources published and distributed over the Internet, the increasing demand for high-performance intelligent information retrieval (IIR) techniques is obvious[1-5]. Most of on-going world-wide researches are exploring intelligent techniques for English document retrieval, while it is always highly desired that such techniques are capable of processing Chinese documents in the community of Chinese[6-10]. In order to pursue high performance of Chinese information access on the Internet, since four years ago a project called Csmart was launched at Academia Sinica. The whole research of the project consists of four major issues: Information Retrieval, Information Filtering and Knowledge Discovery, Speech and Natural Language Interface, and Searching Engines and Language Processing Tools. Each of the issues has two or more research tasks which are fundamental and significant toward the development of intelligent information retrieval are investigating. So far, there are several techniques and real-world applications been developed and some preliminary results obtained[11-22]. In this paper, we are going to have an overview of the whole project in advance and then a brief introduction to each of the research tasks investigated. The main purpose of this paper is to point out the significance of several fundamental research issues and attempts to present some preliminary ideas toward feasible solutions. We hope it will have a little bits of help for researchers who are interested in Chinese Information Retrieval and just finding more challenging problems. For this reason, the remaining sections will be organized as follows: at first, Section II will briefly review the problems of IIR research with the Chinese language, then section III describe each of the ongoing research tasks in short; finally, concluding remarks will be given in Section IV.
II. Problems of IIR Research with the Chinese Language
Information Retrieval (IR) is a research area with a long-term research goal of exploration of information storage, classification, extraction, indexing and browsing techniques for the retrieval of non-structural databases such as textual documents[23]. With the rapid growth in the number of electronic documents published and distributed through the Internet, the significance of more efficient and effective IR techniques is clear, and new research directions have been developed, such as Networked Information Retrieval, Intelligent Information Retrieval and Multi-media Information Retrieval. It is the same motivation which urges researchers in Chinese regions to develop more efficient Chinese IR techniques[6-10]. Over the last two decades, researchers mainly focused on developing efficient indexing schemes for full-text searching, yet without significant achievements. This might have been the result of inherent linguistic difficulties.
Since written Chinese texts lack explicit delimiters between words to indicate the boundaries (Chinese texts appear to be a linear sequence of nonspaced or equally spaced ideographic characters), word segmentation is often believed a prerequisite and taken as the major barrier for Chinese text retrieval[24] . In fact, difficulty of word segmentation do result in many serious problems. First, it makes a word-based Chinese text retrieval system need a prepared dictionary and a sophisticated word segmentation algorithm to perform text segmentation in both of the indexing and searching in advance. Second, since a Chinese sentence can usually be segmented into many different possible word combinations, it is difficult to decide the correct combination (Problem of word segmentation disambiguation) and may cause inconsistency between the word segmentation of documents and queries. Third, because Chinese words are not easily to be clarified with compound words or phrases in common usage, the vocabulary sets are quite different from distinct dictionaries. This causes many proper nouns, such as names and locations, which are usually the keywords in queries and often excluded in the dictionary, are difficult to identify (Problems of unknown word identification). One solution for the above difficulties is to proceed Chinese text retrieval on a character basis, i.e. queries are basically evaluated using character string matching against texts. Problems of character-based approaches would take much more storage demand for indexing and time for searching, cause the difficulty to incorporate a thesaurus and linguistic knowledge, and more importantly, lead of more incorrect matching due to the free combination of characters in sentence.
In addition to the above limitations of the language characteristics, too much effort focused on few research topics, e.g., full-text indexing and searching, does not help but even prevent extension of the scope of Chinese IR. Considering the urgent need to promote of Chinese IR, there are many important research issues which are fundamental and need to be further investigated. These issues include standard text collection, automatic keyphrase indexing, document classification, information filtering, speech and natural language interface, etc., which, however, motivate the research directions of the Csmart project [11].
III. Research Tasks
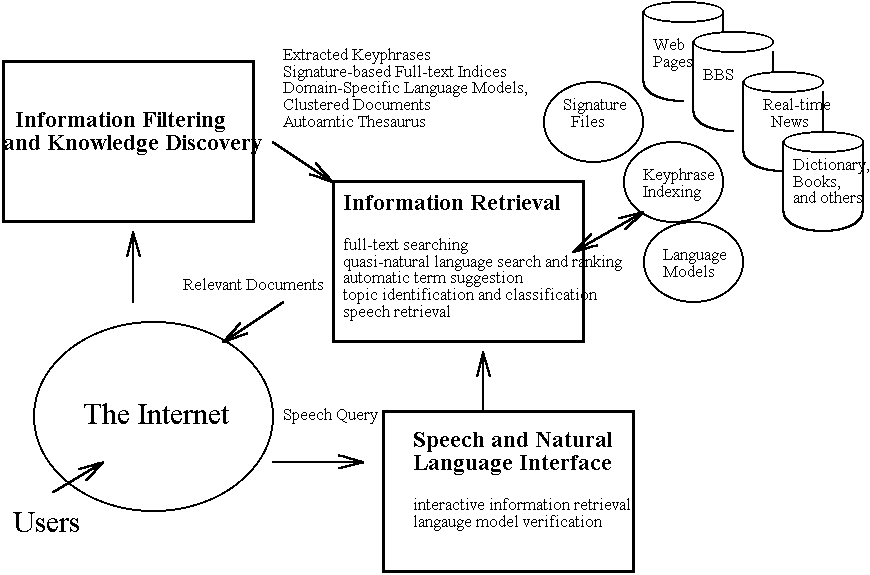
As introduced, Csmart project started with three major theoretic issues: Information Filtering and Knowledge Discovery, Information Retrieval, Speech and Natural Language Interface, and one system developing issue: Searching Engines and Language Processing Tools. First, for access of both textual and audio media and improvement of both retrieval effectiveness and efficiency, we are continuing the development of high-performance text retrieval techniques (3.1) and exploring the feasibility of speech retrieval techniques (3.3.1). Second, in order to extract useful information and linguistic knowledge from the Internet resources for improvements of IR technology, we are currently developing automatic resource discovery techniques to acquire useful Chinese resources, including keyphrase extraction (3.2) to reduce the difficulties of unknown word identification and reliance of Chinese lexicon, and Internet-based language modeling (3.4) in acquisition of linguistic phenomena and semantic knowledge with the change of network resources. Third, for reducing the input difficulty of Chinese characters into a computer and creating an interactive and user-friendly interface in a long run, we are further investigating speech and natural language processing techniques including the technical investigation on Spoken Information Retrieval (3.3.2). Forth, we are looking forward based on the results of the above three research task more sophisticated software including searching engines (4.1), dictation machine (4.2) and other language processing tools can be therefore improved (4.3). The whole research paradigm of Csmart project is them formed as the below figure and each of the research tasks investigated will be described in short in the following including previous results and ongoing research ideas.
3.1 Text Retrieval
3.1.1 Efficient Full-text Search (1994 ~) [12]
In order to have a solid base for IR research, efficiency improvement of text retrieval was the first task to be investigated in 1994. We proposed a fast and efficient specially-designed signature file approach for full-text retrieval of Chinese texts. Basically, this approach is entirely based on careful consideration of the characteristics of Chinese documents, especially on the utilization of semantic disambiguation of Chinese characters and words. It is distinguished from conventional English signature file approaches in two ways: First, it presents an efficient character-based rather than word-based signature extraction method. Second, all of the commonly-used character signatures are automatically generated based on statistical analysis of the database content and a dis-similar character grouping algorithm, rather than simple hashing functions. Because the characteristics of the document database can be properly reflected in the generation of document signature, the probability of false drops is, therefore, effectively reduced. Our experiments show that applying the proposed signature extraction method to retrieving Chinese documents can reduce the average number of false drops for each query more effectively than can the conventional method which simply relies on hashing functions. Furthermore, systems using the proposed signature file approach can achieve even faster retrieval speed compared to that of inversion-based approaches. At the same time, the proposed approach is much more efficient than those inversion-based approaches in many other aspects, for example, in indexing space overhead, approximate text searching and ease of update.
3.1.2 Effective Quasi-Natural Language Search and Document Ranking (1995~)[13]
To remedy the weakness of Boolean queries and develop effective quasi-natural language queries, in 1995 we further developed an extended approach based on the above signature file approach for fast and intelligent retrieval of large Chinese full-text document databases. The proposed approach is an integrated and efficient text access method, which performs well both in exact match searching of Boolean queries and best match searching (ranking) of quasi-natural language queries. Using this approach, the inherent difficulties of Chinese word segmentation and proper noun identification can be effectively reduced, queries can be expressed with non-controlled vocabulary, and the ranking function can be easily implemented neither demanding extra space overhead nor affecting the retrieval efficiency. The best match searching is a two-stage searching process. For each given quasi-natural language query, it first matches the signature of the query against the signature of each document in the database, and filters out most of irrelated documents. Then in the second stage, the remaining documents will be ranked with sophisticated text scanning including dynamic word segmentation and ngram weighting. The experimental results show that the proposed approach achieves good performance in many ways, especially in the effectiveness of best match searching using quasi-natural language queries. The proposed approach, as we know was one of early works which provides quasi-natural language search and is capable of retrieving gigabytes of Chinese texts efficiently.
3.1.3 Ongoing Research
With the above efforts on Chinese text retrieval, conventional difficulties in full-text searching consisting of both efficiency and effectiveness issues have been significantly reduced. Our focus was therefore shifted to resolve the real-world problems for Internet information access. Several new research problems which are taken as urgent were formed. Firstly, in order to reduce the difficulty of little information given from users‘ queries (1.5 English words in average according to experiences of Excite), Automatic Term Suggestion and Query Expansion such as that used in LiveTopic of Altavista is believed will be very useful and worthy to be investigated. To this probelm, we are trying to use PAT-tree-based keyphrase extraction and Chinese word net (to be described in 3.2) for vocabulary expansion from relevant documents and dealing with so-called vocabulary mismatch problem. At the same time, in order to allow both Chinese and English text retrieval concurrently in a text collection or searching engine, approaches for Cross Language Information Retrieval are necessary too. Right now, we are interested in extracting phrase translations directly from bilingual texts. We are trying to develop techniques for classifying English and Chinese documents with same topic into clusters in automatic by document-level mapping, and constructing correlation between Chinese and English keyphrases by phrase-level mapping. In this way, we hope to remedy the weakness of conventional approaches which relied much on using built-in bilingual dictionaries for text retrieval with different languages.
3.2 Keyphrase Extraction
3.2.1 Adaptive Keyword Extraction without Using Lexicon (1996 ~) [14]
.
Considering the urgent need of keyphrase extraction for Chinese texts, automatic keyphrase extraction using a new PAT-tree-based approach was proposed. The proposed Chinese PAT tree does reduce the difficulty of keyword extraction in Chinese, which is critical and fundamental. Using this data structure all possible character strings can be easily retrieved and updated, and the mutual-information-based filtering algorithm can be performed. At the same time, the acquired statistics can be easily adapted with the change of database update. Keywords or keyphrases, such as special proper nouns which were excluded in the general lexicon, are therefore possible to be extracted. Besides, lexical patterns which are incomplete in semantics and lack of representatives can be effectively filtered out. Moreover, the proposed approach is very easy to implement and the reliance on rigid lexicon and sophisticated word segmentation skills can be reduced. In an experiment on extracting keywords and keyphrases out of 10 MB texts, it was found that the precision of extraction can be 80% above and, besides, 40% around of extracted correct patterns are out of a lexicon with a vocabulary of 80,000 words. Since the proposed approach can step ahead the processing from character-level to word/phrase level, as experiments many Chinese language processing applications such as automatic domain-specific term construction, book indexing, automatic term suggestion, relevance feedback and document classification can have significant improvements.
3.2.2 Ongoing Research
Topic Classification and Automatic Thesaurus Construction are the two most interesting problems to be further investigated in the Keyphrase Extraction research task, after the above approach developed. In order to let the extracted keyphrases have more clear semantic discrimination, approaches for semantic labeling are studying. We hope the extracted keyphrases can be labeled with a set of semantic tags such as person, event , time, location and object. In this way, documents with similar topic may be possible to be clustered and the corresponding topic can be highlighted. This would be very helpful in classifying retrieved documents with topics and reducing the difficulty of browsing. On the other hand, the significance of thesaurus in retrieval effectiveness is clear and its construction is expected can be automated. We are investigating if the proposed PAT-tree-based approach can help the research toward automatic thesaurus construction. However, research on this problem is just beginning.
3.3 Speech Retrieval
3.3.1 Syllable-based Approach to Voice File Access (1996) [15]
In order to solve the problem with the new environment of fast growth of audio resources on the Internet, we have presented a syllable-based approach which is capable of retrieving Mandarin voice records using queries of unconstrained speech. Although there exist more than 10,000 commonly used Chinese characters, each character is monosyllabic and the total number of phonologically allowed Mandarin syllables is only 1345. The combination of these monosyllabic characters or 1345 syllables gives almost unlimited number of monosyllabic or polysyllabic words. The proposed approach as we know was one of early works dealing with speech retrieval. By properly utilizing the monosyllabic structure of Chinese language, the proposed approach performed the complete matching process directly at the syllable level using syllable-based statistical information and showed the feasibility to retrieve Mandarin voice files using speech queries. Preliminary experiments were performed and encouraging results demonstrated.
3.3.2 Text Retrieval using Speech Queries (1995) [16]
Use of speech recognition technology in information retrieval for databases provides users with a convenient computer interface environment. For Chinese language, because the language is not alphabetic and the input of Chinese characters into computers is still a difficult and unsolved problem, voice retrieval of Chinese databases, especially of Chinese textual databases, becomes apparently an important application area of Mandarin speech recognition. For this purpose, a syllable-based approach which allows using speech for Chinese textual databases retrieval was presented. The presented approach can reduce most of difficulties of Chinese speech retrieval and easily integrate with the continuous speech recognition technology of the Mandarin dictation machine, Golden Mandarin (III). The experimental results showed that the presented approach is easy to implement and systems based on it can allow users to retrieve Chinese textual databases using spoken queries and unconstrained vocabulary. Although the proposed approach is statistics-based and has some restrictions in linguistic analysis, the achieved results were very encouraging and had shown its feasibility in creating practical applications which demand the recognition ability of very large vocabulary.
3.3.3 Mobile Access of Textual Information Using Speech Queries (1997 ~) [17]
In order to further develop interactive spoken information retrieval techniques based on the previous results, recently we presented an efficient information retrieval approach to accepting speech queries from mobile devices and providing fast information access through network communication. The presented approach carefully considers the characteristics of mobile communication and is basically a successful integration of current speech recognition and information retrieval technology. The approach was performed with an client-server architecture in which automatic keyword extraction and vocabulary-flexible keyword spotting techniques were developed and integrated. Many real-world information services, such as Internet-based Web pages access and Intranet-based e-mail retrieval, are believed can be extended to provide robust speech-driven access via mobile communication. The information access thus can spread from conventional desktop to mobile environment.
3.3.4 Spoken Inquiry (1996 ~) [18]
Investigation on spoken inquiry is for the purpose of extending the scope of spoken information retrieval and toward conversational retrieval. We have developed a statistical approach for speaker intention modeling in application to telephone directory inquiry. Basically, the proposed approach is to predict the speech act type according to user‘s speech inquires. A speech act type is an abstraction of speaker’s intention in terms of the type of action that the speaker intends by utterances. With this approach, spoken dialogue systems can be constructed and has a more proper action in the subsequent processing. An experimental system based on the proposed approach has been developed and the test results proved its efficiency and flexibility to different spoken dialogue applications.
3.4 Internet-based Language Modeling
3.4.1 Improvement of Langauge Modeling with IR techniques (1997 ~) [19]
Natural language processing (NLP) techniques are highly expected for the development of more advanced information retrieval (IR) systems. In fact, not only IR systems can be improved by NLP techniques, there have been found that most of NLP techniques can be also improved with IR techniques and Internet resources. For this purpose, new approaches of natural language modeling based on techniques of NIR were proposed, which consists of using information spider for automatic corpus collection, keyword extraction for lexicon construction, PAT-tree indexing for language model representation, document classification for language model adaptation. Although only preliminary results have been found, it encourages us along this direction to resolve many bottleneck problems and develop more advanced IR systems
3.4.2 Large-scale and Ngram Language Modeling (1997 ~) [20]
Statistical N-gram language models are often used in many NLP systems to estimate the probability of any string of words or characters. For reducing the complexity of model representation, bigram or trigram models are frequently used as an approximation. Of course, this will decrease the power of language modeling. According to our observation, techniques such as PAT-tree indexing used for recording full-text document databases can be more efficient in representing N-gram language model, especially for when the training corpus is large and dynamic. An attractive approach with a successful integration of efficient speech recognition and information retrieval techniques was then proposed recently. In this way, required parameters of a character N-gram model can be extracted directly from the PAT tree, the language model can be easily adapted with the update of the database content and, more importantly, size of training data can be very large. A working system for real-time news retrieval which provides speech recognition interface had been tested with the PAT-tree language model. The performance of the system proves that the conventional difficulties of both the input of Chinese characters and the retrieval of large Chinese texts can be effectively resolved. Besides, domain-specific terms which are often proper nouns such as names, locations but variants and changed with different databases are not difficult to model, because they often have a strong association in their composed sub-strings.
3.4.3 Document Classification and Clustered Language Model (1996 ~) [21]
Language model performance degradation due to different subject domains has always been a serious problem in many NLP applications such as very large vocabulary speech recognition. Adaptation of language models to the specific subject domains is pursued for creating real applications. For this purpose, we are trying to develop language model adaptation method which carefully utilizes Internet resources and IR techniques. The proposed method is basically composed of multiple language models. The training texts used were automatically acquired from the Internet and classified into different subject domains based on parameters such as perplexity and word bigram coverage. In this way multiple domain-specific language models were then trained by first using the domain specific training texts, then interpolating the obtained models with a general domain model. During the training phase, each new section of training texts can be classified to a specific subject domain or used to define a new subject domain by a set of parameters as mentioned above. The interpolation with the general domain models requires only limited training texts for each subject domain. During the recognition phase, limited number of beginning sentences are first linguistic decoded with respect to all the available domain-specific language models, while the decoding scores are used in not only the selection of the final output for these beginning sentences, but the selection of the domain-specific language model to be used for the following input speech. Extensive experiments were performed and significant improvements over using a general model were obtained.
3.4.4 Ongoing Research
In addition to the above problems, the interesting problems on the Internet-based Language Modeling also include Variable-Length Language Modeling and Language Model Verification. Research on variable-length language modeling is to reduce the required parameters of Ngrams but without much decrease of discrimination power. On the other hand, verification of language model is to verify the results of linguistic decoding which are designed based on Markovian language model. Since in most cases errors of linguistic decoding are not many, based on using large volume of training texts and ngram search these errors are expected to be detectable and even correctable in automatic. Applications can be improved with the techniques of language model verification contain spelling checking, OCR and dictation machine. Preliminary results showed that only using a simple approach of language model verification, most of recognition errors of OCR can be detected, and the obtained precision rate can be 0.8 and recall rate 0.6. However, the performance needs further study to prove.
3.5. Experimental Systems and Tools
4.1 Csmart Searching Engine (1995 ~) [22]
Csmart is one of the representative systems with a number of innovative techniques for intelligent Chinese information retrieval. The development of Csmart was based on many of the above research results. Currently, this system is able to provide quasi-natural language search for large volume of Chinese texts and achieves high performance in both efficiency and effectiveness. Besides, it allows users using speech for input. Since 1995 it had produced more than 8 cases of successful technical transfer to industry companies and government organizations in Taiwan including Institute of Information Industry (III), Ministry of Education, Dyna Lab., China Times, etc.. Meanwhile, it also had more than 30 free licenses for research and academic institutions in Taiwan and Hong Kong. The development of Csmart is continued at Academia Sinica.
4.2 Ongoing Language Processing Tools
In addition to the above searching engine, several language processing tools can be further derived from the investigation of the above research topics. Including Voice Keyword Spotter, Keyword Extractor, Spelling Checker and Document Classifier are obviously worthy to be implemented with the execution of Csmart project.
IV. Concluding Remarks
In order to pursue high performance of Chinese information access on the Internet, Csmart was launched at Academia Sinica four year ago. The main purpose of this paper is on the basis of running the project to point out several fundamental research issues and attempts to present some preliminary ideas toward feasible solutions. For this reason, the problems of IIR research with the Chinese language has been briefly reviewed in advance and each of the ongoing research tasks with preliminary technical ideas described in short. In addition, since it is difficult to describe each of the technical contents in details due to the limitation of page length, several relevant publications have been listed in the references. We hope it will have a little bits of help for researchers who are interested in Chinese Information Retrieval and just finding more challenging problems.
Reference
1.Special Issue on “Networked Information Discovery and Retrieval.” Journal of Intelligent Information Systems, 5(Sept. 1995).
2. Belkin, Nicholas J. and Croft, W. Bruce. “Information Filtering and Information Retrieval: Two Sides of the Same Coin?,” Communications of the ACM, 35(Dec. 1992): 29-38.
3. David D. Lewis and Karen Sparck Jones, “Natural Language Processing for Information Retrieval”, communications of the ACM, Vol. 39, No. 1, Jan. 1996, pp. 92-101.
5. D. Lewis, B, Croft and N. Bhandaru, Language-Oriented Information Retrieval, Int' J. of Intelligent System, Vol. 4, 285-318, 1989.
6. Zimin Wu, Gwyneth Tseng, ACTS: An Automatic Chinese Text Segmentation System for Full Text Retrieval, Journal of the American Society for Information Science. 46 (2):83-96, 1995.
7. J. Y. Nie et al., On Chinese Text Retrieval, 1996 ACM SIGIR Conf. on R&D in IR, pp 225-233.
8. T. Liang et al., Optimal Weight Assignment for a Chinese Signature File, Information Processing and Management, No. 2, pp. 227-237, 1996.
9. K. L. Kwok, Comparring Representations in Chinese Information Retrieval, 1997 ACM SIGIR Conf. on R&D in IR, pp34-41.
10. A. Chen et al., Chinese Text Retrieval without using a Dictionary, 1997 ACM SIGIR Conf. on R&D in IR, pp 42-49.
11. Lee-Feng Chien and Hsiao-Tieh Pu, Important Issues on Chinese Full-text Information Retrieval, Computational Linguistics and Chinese Language Processing, Computational Linguistics Society of R.O.C. Press, No. 1, Vol. 1, 205-221, 1996.
12 Lee-Feng Chien , A Model-Based Signature File Approach for Full-text Retrieval of Chinese Document Databases, Computer Processing of Chinese and Oriental Languages, 1995.
13. Lee-Feng Chien , Fast and Quasi-Natural Language Search for Gigabytes of Chinese Texts, ACM SIGIR‘ 95.
14. Lee-Feng Chien. PAT-Tree-Based Keyword Extraction for Chinese Information Retrieval, ACM SIGIR‘97.
15. B. R. Bai, Lee-Feng Chien, L. S. Lee , Syllable-based Relevance Feedback Techniques for Mandarin Voice Record Retrieval Using Speech Queries, Proceedings of the 1997 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP‘97), German.
16. Sung-Chien lin, Lee-Feng Chien, Keh-Jiann Chen, Lin-Shan Lee, An Efficient Voice Retrieval System for Very-Large-Vocabulary Chinese Textual Databases with a Clustered Language Model, Proceedings of the 1996 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP'96).
17. B. R. Bai, Lee-Feng Chien, Lin-shan Lee, Mobile Access of Textual Information Using Speech, submitted to IEEE Transaction on Consumer Electronics.
18. Yen-Ju Yang, Lee-Feng Chien and Lin-Shan Lee, Speaker Intention Modeling for Large Vocabulary Mandarin Spoken Dialogues, Proceedings of the 1996 International Conference on Spoken Language Processing, Oct. 1996 (ICSLP‘96).
19. Lee-Feng Chien, Min-Jer Lee and Hsaio-Tiech Pu, Improvements of Natural Language Modeling Approaches with Information Retrieval Techniques and Internet Resources, The 1997 International Workshop on Information Retrieval with Asian Languages, Japan (IRAL‘97).
20. Lee-Feng Chien ,Sung-Chien Lin, et al., Internet Chinese Information Retrieval Using Unconstrained Mandarin Speech Queries Based on A Client-Server Architecture and A PAT-tree-based Language Model, Proceedings of the 1997 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP‘97), German.
21. Sung-Chien Lin, Lee-Feng Chien, Lin-Shan Lee,Multi-language Model for Mandarin Speech Recognition, EuroSpeech‘97, Greece.
23. Salton, G., Introduction to Modern Information Retrieval, NY, McGraw-Hill, 1983.
24. Keh-Jiann Chen et al., Word Identification for Mandarin Chinese Sentences, COLING'92.